After many trials and errors, my Mediawiki install seemed to finally be on a good footing, with load on our 8 core server being between about 1 to 2-ish generally. Then, for no apparent reason, after several days of being fine, load suddenly ramped up wildly. Initial diagnosis from our tech people was high traffic from the Bytedance and Bytespider botnet. We blocked that, and a couple of others. Load fell.. but only a little.
I have since tried a number of things, like switching from PHP 8.2 to PHP 7.4, and that seems to be much better. But why? It worked for days, then stopped working well, and I don't know why. And it's not like 7.4 is perfect, either -- even modest loads can push it to 7.0 to 8-ish, which means 100% CPU usage. Right now it's sitting at 6.5 average load with an average of 30 requests per second, of which the vast majority are going to cache. This _should_ be a piece of cake for this server and LSWS.
So, this brings me around to the title: am I starving LSWS of RAM? The one thing I have noticed during all of this, even the one time load shot up to a reported 100, and MySQL connections were at 275, so there were hundreds of requests, used RAM barely budged above 12GB (on a 64GB server), and factoring in the 3GB used by MariaDB and the 4GB used by Redis, that meant that LSWS and its PHP processes were actually only touching something around 5GB of RAM.
On the one hand, the extremely efficient resource use of LSWS is great. But on the other hand, there _is_ (a lot) more RAM available and it should use it when it needs it to speed up processing of requests.
Further, why would 8.2 work so well and then suddenly turn terrible? I can't see any obvious errors in logs that would explain this. I'm considering recompiling 8.2 just to see if maybe there's some random corruption, but that seems a long shot.
General configuration notes:
Computer: E3-1260 v4, 64GB RAM, SSD drives
LSWS: Using LS Cache with Mediawiki plugin, LSWS version 6.1.1 (rolled back from 6.2.1 just to see if that affected anything.
Server > General: PHP suEXEC Max Conn = 200
Server > Tuning: Max Connections & Max SSL Connections = 1000, Connection Timeout = 30 secs, Max Keep-Alive Requests = 10000, Keep-alive Timeout = 5, HTTP3/QUIC = Yes
Server > Cache: Cache Features = On and Crawler (taking off Crawler made no change to the issues we're having)
Server > PHP: Environment = PHP_LSAPI_CHILDREN = 500 and LSAPI_AVOID_FORK = 1, Max Connections = 1500, Initial Request Timeout = 60, Connection Keepalive Timeout = 1, Max Idle Time = 86400, Memory Soft/Hard Limit = 2047M, Process Soft Limit = 400, Process Hard Limit = 500
Server > External App > PHP74: Max Connections = 1500, Environment = PHP_LSAPI_CHILDREN = 1500, Persistent Connection + Yes (changing this made no difference)
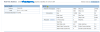
ETA: Attaching an image after a recent graceful restart to give a sense ofw hat I'm seeing. Any tips for how to improve our situation are very welcome! I know LSWS can do way better than it is doing right now, so it's surely my fault somehow, but I'm at a loss to figure it out, as are the people who help manage the server for us.
I have since tried a number of things, like switching from PHP 8.2 to PHP 7.4, and that seems to be much better. But why? It worked for days, then stopped working well, and I don't know why. And it's not like 7.4 is perfect, either -- even modest loads can push it to 7.0 to 8-ish, which means 100% CPU usage. Right now it's sitting at 6.5 average load with an average of 30 requests per second, of which the vast majority are going to cache. This _should_ be a piece of cake for this server and LSWS.
So, this brings me around to the title: am I starving LSWS of RAM? The one thing I have noticed during all of this, even the one time load shot up to a reported 100, and MySQL connections were at 275, so there were hundreds of requests, used RAM barely budged above 12GB (on a 64GB server), and factoring in the 3GB used by MariaDB and the 4GB used by Redis, that meant that LSWS and its PHP processes were actually only touching something around 5GB of RAM.
On the one hand, the extremely efficient resource use of LSWS is great. But on the other hand, there _is_ (a lot) more RAM available and it should use it when it needs it to speed up processing of requests.
Further, why would 8.2 work so well and then suddenly turn terrible? I can't see any obvious errors in logs that would explain this. I'm considering recompiling 8.2 just to see if maybe there's some random corruption, but that seems a long shot.
General configuration notes:
Computer: E3-1260 v4, 64GB RAM, SSD drives
LSWS: Using LS Cache with Mediawiki plugin, LSWS version 6.1.1 (rolled back from 6.2.1 just to see if that affected anything.
Server > General: PHP suEXEC Max Conn = 200
Server > Tuning: Max Connections & Max SSL Connections = 1000, Connection Timeout = 30 secs, Max Keep-Alive Requests = 10000, Keep-alive Timeout = 5, HTTP3/QUIC = Yes
Server > Cache: Cache Features = On and Crawler (taking off Crawler made no change to the issues we're having)
Server > PHP: Environment = PHP_LSAPI_CHILDREN = 500 and LSAPI_AVOID_FORK = 1, Max Connections = 1500, Initial Request Timeout = 60, Connection Keepalive Timeout = 1, Max Idle Time = 86400, Memory Soft/Hard Limit = 2047M, Process Soft Limit = 400, Process Hard Limit = 500
Server > External App > PHP74: Max Connections = 1500, Environment = PHP_LSAPI_CHILDREN = 1500, Persistent Connection + Yes (changing this made no difference)
ETA: Attaching an image after a recent graceful restart to give a sense ofw hat I'm seeing. Any tips for how to improve our situation are very welcome! I know LSWS can do way better than it is doing right now, so it's surely my fault somehow, but I'm at a loss to figure it out, as are the people who help manage the server for us.
Attachments
-
 32.2 KB Views: 7
32.2 KB Views: 7
Last edited:

