OK, maybe Litespeed itself isn't buggy but the opencart plugin is... For example, if I edit just one product the plugin removes the cache for all products instead of just the one.
I see a lot of hate for Journal and I have no idea if it's warranted or not but it's very popular so I would hope everyone could just come together. Isn't Wordpress a third party type situation?
I see a lot of hate for Journal and I have no idea if it's warranted or not but it's very popular so I would hope everyone could just come together. Isn't Wordpress a third party type situation?
OK, maybe Litespeed itself isn't buggy but the opencart plugin is... For example, if I edit just one product the plugin removes the cache for all products instead of just the one.
") But not with plugin!
But not with plugin!Create a blank php file and copy the code below into this file.
Code:
<?php
header('X-LiteSpeed-Cache-Control: no-cache');
header("X-LiteSpeed-Purge: /url_of_page_you want_to_purge_the_cache"); // but without hostname@AndreyPopov
If you want to harden if Safari supports webp images or not you must inspect all other header that are sent within a request. One of the most important header for detection if a browser supports whatever is the "Accept" header. Every browser sends this header, but each browser sends different information, but many values are common. To detect if a browser independently if it is a Apple device or not check if Accept header has this value. You can use this in cache rules like UA.
Combine this condition with other and define cache rules that are more reliable.
If you want to harden if Safari supports webp images or not you must inspect all other header that are sent within a request. One of the most important header for detection if a browser supports whatever is the "Accept" header. Every browser sends this header, but each browser sends different information, but many values are common. To detect if a browser independently if it is a Apple device or not check if Accept header has this value. You can use this in cache rules like UA.
Code:
RewriteCond %{HTTP_ACCEPT} "image/webp"
RewriteRule .* - [E=Cache-Control:vary=is_webp]
Yes, I am shure! "Chrome" is part of Googlebot user agent, so if you exclude Chrome from Googlebot UA you exclude Googlebot!
"Chrome" is part of Googlebot user agent, so if you exclude Chrome from Googlebot UA you exclude Googlebot!
help me find "Chrome" string in Googlebot UA
Code:
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)P.S. when "find" I answer for your others wrong sentences.
P.S.P.S. you hear only yourself!!!!
@AndreyPopov
To detect if a browser independently if it is a Apple device or not check if Accept header has this value. You can use this in cache rules like UA.
To detect if a browser independently if it is a Apple device or not check if Accept header has this value. You can use this in cache rules like UA.
Last edited:
How do I help Curl from crashing and timing out every few minutes? Any settings I can change?
I have to sit in front of the computer and babysit this when rebuilding cache so I can constantly restart the script, very annoying!
The error:
curl: (18) transfer closed with outstanding read data remaining
I have to sit in front of the computer and babysit this when rebuilding cache so I can constantly restart the script, very annoying!
The error:
curl: (18) transfer closed with outstanding read data remaining
first check php memory limit!
when my hoster sets 1024MB php memory limit and number of products of my site became more than 4500, I very often see curl errors and that's why I made my "advanced crawler" mode.
store in php memory all links (that must be recached) can exceed memory limit.
I made 4096 links per run, than decrease to 2048 and finally use 1020 links per run.
I use crontab tasks for run recache scripts.
Last edited:
ask you again: ARE YOU SURE!?!?!?!?!?!!?!?!!
help me find "Chrome" string in Googlebot UA
I'm waiting ......
P.S. when "find" I answer for your others wrong sentences.
P.S.P.S. you hear only yourself!!!!
I wrote to you that JOURNAL decide what image type provide!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
help me find "Chrome" string in Googlebot UA
Code:
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)P.S. when "find" I answer for your others wrong sentences.
P.S.P.S. you hear only yourself!!!!
I wrote to you that JOURNAL decide what image type provide!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.41 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
I wrote to you that JOURNAL decide what image type provide!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.41 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
OPEN your eyes and FREE your mind!!!!!!!
this is MOBILE Googlebot UA!!!!!!!!!!!!!!
are you see string "Mobile"?!?!?!?!?!?!?
and for Mobile Googlebot UA and Journal Mobile View exist next rule:
Code:
RewriteCond %{HTTP_USER_AGENT} Bot [NC]
RewriteCond %{HTTP_USER_AGENT} Android [NC]
RewriteCond %{HTTP_USER_AGENT} Chrome [NC]
RewriteRule .* - [E=Cache-Control:vary=ismobilebot]or you only can bla-bla-bla-bla about nothing matter things?
If Journal would do that, then you have to do nothing
to expand edges of your mind I tell you something:
- I NOT load to backend webp images
- I load jpg(png) images
- I check in Journal3 settings option "System->Perfomance->Images->Compression (Beta)" that enable Journal's conversion jpg(png)->webp
- Journal detect by UA what device Desktop/Tablet/Mobile and Chrome compatible/Safari and provide:
name_500x500.jpg.webp for Desktop (Chrome compatible) or name_1000x1000.jpg.webp for Mobile(Chrome compatible)
name_500x500.jpg for Desktop Safari or name_1000x1000.jpg for Mobile Safari
but LSCache by default break this algoritm!!!
because LSCache provide already build page!
to correct work LSCache and Journal must be separate cache generaed for each variants!!!
Last edited:
Anyway, it is nonsense what you are doing. You have minimal ressources on your server and you use totally wrong parameters for curl. Why do you stress your server with useless processes you don't have any advantage from. I know nowbody who does that. Anyway, do whatever you think it is okay, especially you are resistent against any help.....
especially you are resistent against any help.....
you NOT understanding how Journal work.
I tell you previously that most of my questions implemented by developers to LSCache Opencart Plugin and even some code I provided
https://github.com/litespeedtech/lscache-opencart/commit/dc4a7642e39e08788bdc07a00607043f47e58c66
---------------------------------------------------
I'm still waiting for your find "Chrome" string in Desktop Googlebot UA!
---------------------------------------------------
The error:
curl: (18) transfer closed with outstanding read data remaining
curl: (18) transfer closed with outstanding read data remaining
https://stackoverflow.com/questions...r-closed-with-outstanding-read-data-remaining
default settings for curl in plugin is
/catalog/controller/extension/module/lscache.php
Code:
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, false);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
curl_setopt($ch, CURLOPT_MAXREDIRS, 1);
curl_setopt($ch, CURLOPT_HTTP_VERSION, CURL_HTTP_VERSION_1_1);I use next:
Code:
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, true);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, 2);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
curl_setopt($ch, CURLOPT_MAXREDIRS, 4);
curl_setopt($ch, CURLOPT_HTTP_VERSION, CURL_HTTP_VERSION_2);
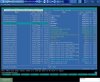
see attachment
3500 URLs in 3 minutes..... at your host
3500 URLs in 3 minutes..... at your host
lscache store folder not increase.
this a same like this https://check.lscache.io/
Last edited:
This is the proof that you don't understand anything. You can't check only check if cache status is hit or miss. If a page is requested and its status is miss, the page will always be cached and is hit after this request. If you check your page with https://check.lscache.io/ the requested URL is cached after the check. https://check.lscache.io/ does the same what I do and also you could do that, but you don't want to understand!
but you don't want to understand!
page of my site stored in cache from 60KB to 600KB
your 3464 requests must generate from 200MB to 2GB cached pages (in my expirience ~1GB)
but your requests not generate anything!!!!
storage usage 23.05.2022 from 12:00 to 20:00 NOT change!!!!!
If a page is already cached there are no more additional cache files in cache directory and most of the requested URL were already cached, so you argues with wrong arguments Furthermore the cached files are compressed and only HTML Output is cached and not static sources like images, css and so on. In sum that are only a few kb to store in cache files, but only if a URL isn't not cached.
I'd like to reveal the secret how and what to do to speedup your crawling, but you always block to learn, so why should it I do it? Then you just stay stupid....
Furthermore the cached files are compressed and only HTML Output is cached and not static sources like images, css and so on. In sum that are only a few kb to store in cache files, but only if a URL isn't not cached.I'd like to reveal the secret how and what to do to speedup your crawling, but you always block to learn, so why should it I do it? Then you just stay stupid....